进入2025年迪士尼彩乐园怎么下载,推理讲话模子RLM动手大爆发。继OpenAI O1发布、DeepSeek火爆之后,包括X.ai、Anthropic、阿里千问、月之暗面在内的国表里大模子厂商纷纷跟进,最新的模子加快发布,前沿的立异算法接续袒露。
对普通磋议者而言,推理讲话模子(如OpenAI的o1、Alibaba的QwQ等)因其高本钱、专有性质和复杂架构,微型团队难以企及。
对于大家而言,贯穿推理模子磋议时间的门槛依然很高。
近期,苏黎世联邦理工学院的学者们发布了一篇论文《Reasoning Language Models: A Blueprint》(邻接:https://arxiv.org/pdf/2501.11223),通过对现存RLM责任的平日调研和分析,提议了一个模块化的蓝图框架,将RLM的构建阐明为几许关键组件,如推理结构、推理政策、算子、老师范式等,赞成活泼构建各类 RLM。
对磋议东说念主员而言,通过将复杂的RLM遐想抽象为可组合的模块,镌汰了表面磋议的门槛,促进了学术界对推理模子的长远探索和圭臬化。
对于想了解推理模子的读者而言,这亦然一篇好的初学材料,不错匡助读者更好的贯穿RLM模子,以及贯穿磋议员门门是何如遐想RLM的。因此,锦秋基金也作念了一些编译。
需要阐明的是迪士尼彩乐园怎么下载,这是一篇初学的科普著述,共享了推理讲话模子RLM的一些基础的成见、经过、组件、构建想路,并未波及到面前推理讲话模子RLM的一些新的算法想路与立异,尤其是在推理磋议的探索与立异。这部分,咱们也会在近期以挑升的著述或者共享来作念下磋议的呈现。
为了大家更好的阅读这篇著述,咱们在这里先提供一个简短的阅读框架。
这篇著述中,你将会了解到:
01 RLM的演进与基础:RLM 会通 LLM 的学问广度、RL 的探索深度和高性能计算(HPC)的赞成,兑现从直观式瞻望到系统化问题不断的跃迁。
02 RLM的基本经过:RLM 架构由推理、老师和数据生成三大经过组成,其中推理过程通过树状结构和蒙特卡洛树搜索(MCTS)系统化探索不断决议。
03 RLM的推理模子组件:RLM的推理模子遐想包括了推理决议、算子、模子、老师范式、老师数据范围和管线等组件。
04 何如遐想RLM模子:构建 RLM,需界说推理决议(结构与政策)、选拔算子并细目模子老师细节,以适配特定任务需求。
05 有用的RLM构建训戒:基于面前的实践,构建 RLM 的有用训戒包括基于过程的评估、两阶段老师(SFT+RL)、高质料老师数据的使用,以及严慎应用 LLM 自我批判。

01
推理讲话模子(RLM)的演进与基础
1.1推理模子的基础
推理讲话模子(RLM)的进展主若是会通了三大时间跳跃:
(1) 诸如 GPT-4 等 LLM 的跳跃;
(2) 诸如 AlphaZero 等强化学习(RL)遐想;
(3) 高性能计算(HPC)资源。
这些身分共同塑造了一种不详高效践诺“系统 2 想维”的模子,会通了显式推理和新颖问题治明智力,这与“系统 1 想维”那种直观式、快速且自动化的启发式酿成明白对比。
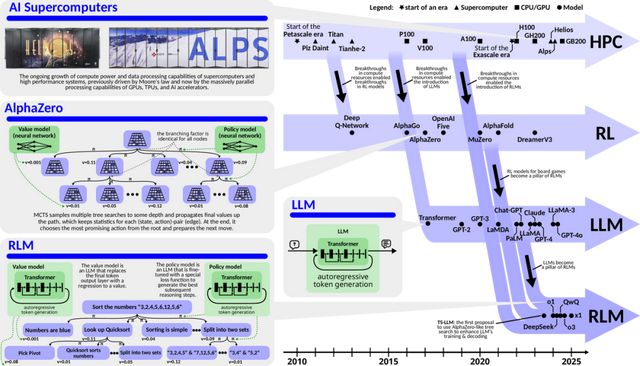
接下来咱们将简要解释下这三个身分的基本成见。
大型讲话模子(LLMs),举例 GPT-4o,是基于海量文本数据老师的东说念主工智能系统。这种老师赋予了它们丰富的天下学问,并使它们不详运动地贯穿和生成天然讲话,使其在处理各类讲话磋议任务时施展出色。
可是,大型讲话模子的推明智力更倾向于直观式的关联瞻望,这与东说念主类大脑的“系统1想维”模式相似。
它们主要依赖统计模式来瞻望序列中下一个可能的词语,而非通过严谨的逻辑推演来不断问题。因此,在需要深度分析和复杂推理的场景中,大型讲话模子的智力就显得有所欠缺。
强化学习(RL)手脚一种通过试错学习最优政策的框架,在某些领域展现出超卓的智力,举例 AlphaZero 在棋类游戏中就施展出了超越东说念主类的水平。它不详从零动手,通过自我对弈徐徐掌持茂盛的政策,以致发现东说念主类众人未始料想想的立异解法。
可是,强化学习的不及之处在于,它常常枯竭平日的践诺天下学问,因此在班师处理那些需要丰富布景信息才能贯穿的多维度任务时,会显过劲不从心。
高性能计算(HPC)是复古大型讲话模子和强化学习发展的关键基石。跟着传统摩尔定律的增长渐渐放缓,高性能计算通过并行计算、异构架构(如 GPU 和 TPU)以及数据并行、模子并行等时间,冲突了算力瓶颈,使得老师和部署大鸿沟模子成为践诺。
因此,如果不详结合大型讲话模子的学问广度和强化学习的探索深度,并依托高性能计算提供的遒劲算力赞成,咱们就有望构建出兼具重大学问和超卓推明智力的 AI 系统,从而更有用地不断复杂的践诺问题。
这种会通将使东说念主工智能系统从依赖内插法、生成与老师数据相似回话的传统大型讲话模子(LLM),进化为不详通过外推法探索未知领域、主动不断问题的推理讲话模子(RLM),兑现从模式补全到主动问题不断的飞跃。
1.2 隐式推理与显式推理
为了更长远地贯穿推理讲话模子(RLM)的责任机制,咱们不错凭据其推理过程的兑现方式,将其进一步诀别为隐式推理讲话模子和显式推理讲话模子两大类别。这两种模子在推理的透明度、活泼性以及问题治明智力等方面存在显贵互异。
隐式推理模子
这类模子的一个中枢特色,即是将推理结构完全融入到了模子自身的权重之中。 咱们不错将这类模子设想成一个“黑盒子”,举例 QwQ 模子即是其中一个代表。它们的推理过程是内嵌于模子里面的,对于外部不雅察者而言,其运作机制是不行见的,也难以东说念主为限制。
尽管如斯,隐式推理模子比较于普通的 LLM,常常展现出更强的推明智力。
可是,值得在意的是,它们的推理过程枯竭透明度,而且很猛进度上依赖于老师阶段所学习到的数据模式,这在一定进度上限制了其活泼性和可解释性。
显式推理模子
与隐式推理模子一龙一猪的是显式推理模子。这类模子采选了一种更为洞开和可控的政策:它们引入了孤独于模子中枢权重的显式推理机制。
在繁密显式推理模子中, LLaMA-Berry、Marco-o1 以及 OpenAI 的 o3 (可能包括)等模子是典型的代表。
这些模子的一个共同特征是,它们微妙地会通了举例显式蒙特卡洛树搜索(MCTS)与强化学习等机制来进行决策。
这种显式的结构赋予了模子独有的上风:它不详迭代地进行模拟、评估和优化潜在的不断决议,从而有用地促进立异性的问题不断和更遒劲的外推智力。
更蹙迫的是,通过将推理过程从那些编码在权重中的静态学问中解耦出来,显式推理模子在践诺推理任务时,展现出更高的活泼性和可解释性,这为咱们贯穿和改进模子步履提供了可能。
临了,还需要补充阐明一丝,天然显式推理赋予了模子诸多上风,但根由的是,显式推理过程自己不错通过老师被模子渐渐内化,并最终障碍为隐式推理,这暗意着两种推理方式之间可能存在着某种潜在的磋议与障碍。
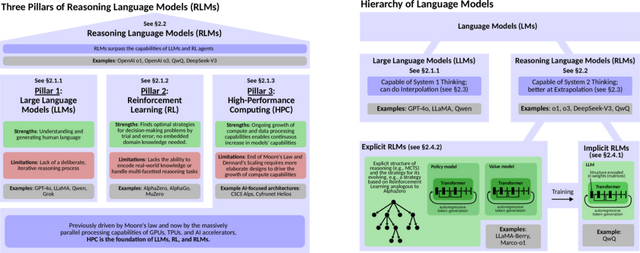
了解了推理讲话模子的基础成见与推理机制后,接下来咱们将长远探讨其基本架构、中枢经过与关键成见,从而更全面地意志 RLM 的运作方式。 咱们将从 “是什么” 转向 “何如作念”,揭示 RLM 兑现推明智力的系统性遐想。
02
RLM的基本架构、经过和成见
下图从三个层级展示了RLM架构的细节。总体而言(左上部分),好意思满的 RLM 架构由三大主要经过组成:推理 (Inference)、老师 (Training)和 数据生成 (Data Generation)。
推理经过负责反应用户的苦求,并利用 老师经过所提供的模子(举例,价值模子或政策模子)进行责任。
数据生成经过在里面遐想上与推理经过互为镜像;其主要区别在于,数据生成经过孤独于用户苦求而运行,其目的是生成数据,用于模子的持续再老师。
因此,老师经过与来自不同领域的 数据生成经过相结合,赋予了 RLM 自学习的智力,这与 AlphaZero的 自对弈成立有一口同声之妙。
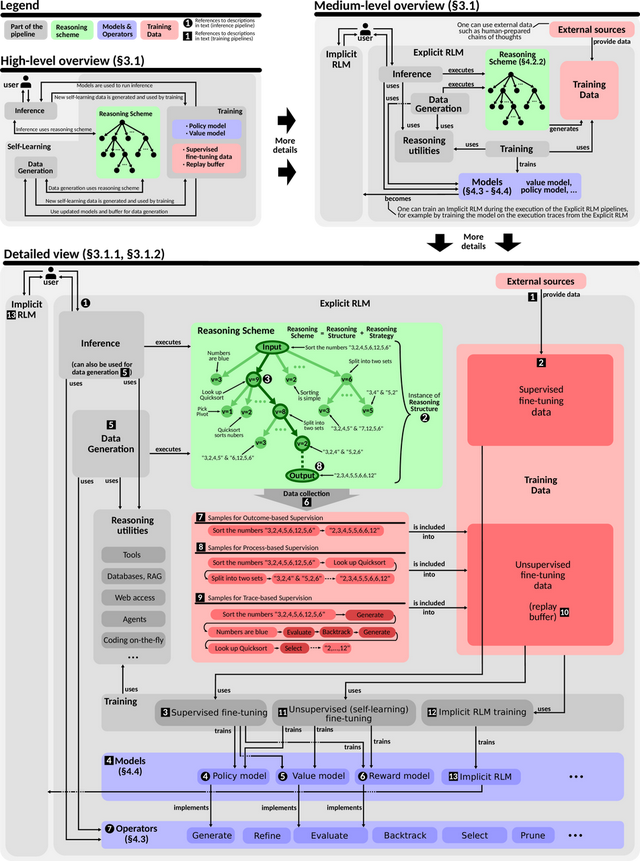
2.1 推理
推理过程从用户提供的输入教导词动手,这一教导词常常描摹了RLM需要不断的具体问题或待回答的疑问。输入教导手脚推理过程的根节点,由此伸开推理结构的构建。
这一结构旨在有序地组织和教授RLM的推理过程,并常常呈现为树状时势。树的根节点对应用户的开动输入,后续生成的节点则用于探索搜索空间,即通盘可能的推理旅途或潜在不断决议的领域。推理结构的中枢主张在于系统性地寻找潜在不断决议,通过徐徐完善和拓展推理旅途,最终得出最优或令东说念主清闲的谜底。
在搜索空间中,每一个孤独点在推理结构中施展为一个节点,对应一个推理表率。推理表率是一个连贯且自洽的想想单元,由一系列词元(tokens)组成。
它通过探索问题的新分支或深化已有进展,推动不断决议的演进。这些推理表率是组成通盘这个词推理过程的基本组成部分。
推理结构的膨胀由蒙特卡洛树搜索(MCTS)主导,其遐想灵感源自AlphaZero,旨在高效且有针对性地探索有出路的旅途。
MCTS依赖政策模子和价值模子的辅助。政策模子在每个节点生成新的推理表率,瞻望最有可能的下一步,以膨胀推理过程;价值模子则评估从某节点登程的推理旅途的质料,教授系统优先探索最有但愿的标的。此外,在某些情况下,奖励模子会被用来评估单个节点偏执推理表率的优劣。
搜索和推理过程将持续迭代,直至达到拒绝表率。拒绝表率象征着一条推理链的斥逐,这条推理链酿成了针对用户问题的最终谜底。在推理树中,它手脚叶节点,宣告特定推理旅途的完毕。
这一架构提供了一个长入的框架,不详活泼适当各式推理任务。岂论是细粒度的推理表率(举例单个词元序列),如故粗粒度的推理表率(举例将好意思满推理链视为单一节点),该架构均可无缝适配。
通过明确构建搜索空间,并利用政策模子和价值模子教授探索标的,RLM最终兑现了在直观式模式识别与审慎问题不断之间架起桥梁的推明智力。
2.2 老师
老师的具体细节取决于所老师的模子类型,举例价值模子、政策模子或奖励模子等。
一般来说,咱们常常经受微调的方式来老师诸如Llama这么的预老师模子。具体作念法是,当先利用监督数据进行老师,这些数据往交游源于已有的数据集,比如PRM800K。这些数据集为监督老师经过提供了必要的数据赞成,用于老师蓝图中所波及的部分或一皆模子。
在RLM(强化学习模子)的举座老师框架中,除了监督老师除外,另一个蹙迫组成部分是无监督(自学习)老师经过。在这也曾过中,老师数据是持续生成的,并被用于模子的迭代优化。这些数据不错通过以下两种方式赢得:
从推理经过中汇集:前提是实施了严格的质料限制,以确保数据可靠性。
从挑升遐想的合成数据生成经过中赢得:这种经过在遐想上与推理经过相互镜像,具有对称性。
为了汇集这些数据,咱们需要针对特定的输入任务运行相应的RLM经过,并纪录其斥逐。凭据数据汇集的精细进度,所得数据可能包含不同的标签类型,举例:
基于轨迹的标签:这是咱们蓝图中提议的一种变体,它是对基于过程的标签的膨胀,进一步包含了任务不断过程中所使用的算子(即操作或门径)信息。
有汇集到的数据都会被存储到回放缓冲区中,并在无监督老师决议中加以利用。这些数据不仅赞成面前的模子老师,还可能为异日的隐式RLM模子提供基础。
2.3 其他RLM架构
上述描摹的老师遐想决议适用于很多RLM架构。可是,RLM领域仍存在多种其他的架构变体,其中一些与咱们提议的框架并不完全一致。
举例,在某些RLM遐想中,蒙特卡洛树搜索(MCTS)中的单个节点不错代表一个好意思满的推理结构,比如一条好意思满的推理表率链。而其他一些架构则引入了更为立异的范式,其中一种被称为“旅程学习”(Journey Learning)。
这种范式通过引入障碍表率加多了复杂性。这些障碍表率不详“重塑”搜索或推理结构,将树中的多条旅途进行整合,并将其合成为一种全新的时势,手脚后续推理迭代的输入。
接下来咱们将看到,RLM蓝图何如将之前参谋的推理决议、算子、模子以及老师门径等身分系统地组织起来,为遐想和兑现各式功能遒劲的 RLM 提供表面复古和实践领导。
03
RLM的组件用具箱
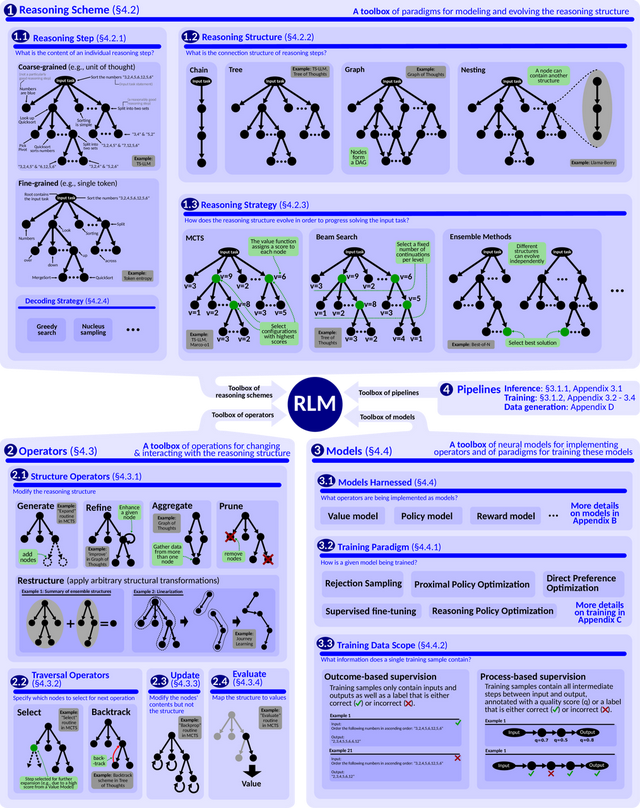
RLM(推理讲话模子)的蓝图旨在提供一个组件用具箱,利用这些组件不错构建各式类型的推理讲话模子。组成RLM蓝图的中枢身分不错归纳为以下几点:
推理决议 (Reasoning Scheme):这是RLM的骨架,它明确界说了模子进行推理时的结构和政策。
推理结构: 举例,不错经受树状结构来组织推理过程。
推理政策: 举例,不错使用蒙特卡洛树搜索(MCTS)等政策来领导推理结构的演进。推理政策的作用是领导推理结构何如发展,以便有用地不断给定的任务。
算子 (Operators): 这是一组不错应用于推理结构的用具,由推理政策来领导使用,目的是徐徐演化推理结构,使其在不断任务的过程中接续跳跃。
模子 (Models): 这是指算子兑现功能时所依赖的各式神经汇集模子,以及这些模子的老师门径。举例,前文提到的“政策模子”以偏执相应的老师范式都属于此类组件。
管线 (Pipelines): 管线是操作的驻守表率,它谐和推理决议与算子之间的互动,以兑现特定的主张。这些主张不错是多种各类的,举例模子老师、推理瞻望或数据生成等。
总的来说,一个好意思满的RLM不错被界说为以下几个部分有机结合的举座:推理决议、一组算子及磋议模子,以及一组管线。它们相互谐和,共同组成了一个功能完善的推理讲话模子。
3.1 推理决议
推理决议驻守轨则了推理表率的细节偏执结合方式,确保模子不详徐徐完成问题求解。它不仅描摹了何如将推理表率组织成链状、树状或更为复杂的结构,也阐发了这些结构在求解输入任务时何如动态演化。
推理表率
推理表率是推理结构的基本单元,由一系列 tokens 组成,驱动 RLM 向不断决议鼓舞。每个表率的长度可从单个 token 到好意思满文本不等,粒度可凭据遐想需求活泼调度。
在现存决议中,推理表率常常被视为“连贯且自成一体的想想单元”,举例在数学讲明中,一个表率常对应于一个孤独的逻辑论证或演绎。
更粗粒度的推理表率(如好意思满的逻辑论证)有助于简化数据准备并提高可解释性;而更细粒度的表率(如 single-token)则能显式纳入模子的不细目性,并整合诸如推测解码或对比解码等高等解码决议。
不外,当需要与搜索算法(如 MCTS)结合时,细粒度的推理表率常常会带来更高的计算需求。
推理结构
推理结构轨则了各个表率何如结合与组织,典型时势包括链状、树状和图状。
链状结构 以线性的方式鼓舞,每个表率都建造在前一个表率的基础上。这在基于想维链 (CoT) 的模子中十分常见。
树状结构 则在每个节点产生疏支,酿成决策树,常用于基于 MCTS 的框架,可通过同期探索多个潜在旅途来寻找最好解,但复杂度与本钱也相应加多。
图状结构 允许推理表率间存在职意依赖关系,赞成基于图的推理,举例想维图 (GoT)。进一步的推行时势包括嵌套结构,举例在 LlaMa-Berry 中,一个树状结构节点自己可包含一个 CoT 链,用于多表率任务的分层组织。磋议者也可能经受超图或模体 (motif) 等更高阶结构,以适当更复杂的推理场景。
推理政策
推理政策决定了推理结构何如演变,以及何如将新的推理表率整合进已有结构。常赐教例包括:
MCTS:通过在搜索树中模拟多条旅途并依靠评分函数选拔最好分支,均衡探索与利用。
束搜索 (Beam Search):在每个表率保留固定数目的名次靠前候选,用于生成 token 序列,迪士尼彩乐园也可膨胀到推理表率的选拔上。
集成门径 (Ensemble Methods):团员多个孤独的推理政策以提高鲁棒性和准确性,举例 Best-of-N 生成多条推理旅途后考中最好解,或树集成(丛林,Forest)在多棵不连通的树之间并行搜索并最终聚集。
需要在意的是,应将推理政策与解码政策区分开来。解码政策(如绸缪搜索)负责在单个推理表率内生成具体 tokens,而推理政策则着眼于在较高头绪上何如衔尾和膨胀这些表率。
3.2 算子
在明确了推理政策的举座框架后,需要一系列算子来对推理结构进行操作,以鼓舞或优化推理过程。本文给出的算子主要分为以下几类:结构算子、遍历算子、更新算子和评估算子。
结构算子
结构算子通过对推理结构进行修改来添加或直爽推理表率,常见类型如下:
生成 (Generate):向推理结构中添加新的或多个推理表率。在 MCTS 中,“生成”算子常常由政策模子兑现;在其他政策(如 CoT 或束搜索)中则可能进行线性或并行的表率追加。
直爽 (Refine):对现存表率进行改进,如覆没歧义、纠正造作或增强明晰度,并生成改进后的版块。可借助自我批判、摘抄、改述等机制来提高表率的准确性与连贯性。
团员 (Aggregate):将多个推理表率、旅途或结构统一为单个后续表率,整合信息或加强连贯性。常见于集成门径和想维图中。
剪枝 (Prune):移除推理结构中被判定为次优或不磋议的节点,以镌汰 token 本钱并提高服从。
重构 (Restructure):对推理结构进行更活泼的变换,举例将树状结构再行组织为线性链,以便在长入高下文下整合来自不同分支的洞见。
在应用结构算子时,生成斥逐的各类性尤为关键,可通过政策模子温度、各类束搜索等路线教授更各类化的输出。在 MCTS 中,“探索”和“利用”相同不错通过树置信上限 (UCT) 等公式谐和,影响生成的新分支数目。
遍历算子
遍历算子决定了在已有推理结构中何如进行导航:
选拔 (Select):基于启发式评分或搜索政策(如 PUCT、UCT)选出最具后劲的候选表率进行进一步探索或直爽。
回溯 (Backtrack):显式复返到先前的推理表率并沿其他旅途接续推理,用于造作纠正、假定更正或发散想考。
更新算子
更新算子在不改造推理结构举座时势的情况下,沿现存的表率或节点进行信息回传或内容增强。举例,MCTS 中的反向传播会沿着伸开的分支回传评分,想维图则可能对节点内容进行屡次增强,以迭代升级推理质料。
评估算子
评估算子会对推理结构的部天职容输出一个数值或主张,而不修改结构自己。典型场景包括:
在具备明确谜底的任务中,对拒绝情状进行正确性或好意思满性评估。
针对非拒绝表率进行启发式或基于价值模子的评估,以测度某一表率对最终正确解的潜在孝敬。
使用价值测度器或奖励模子,从正确性和对举座解的进展进度两方面掂量推理表率价值。
3.3 Test-Time Compute
比年来,大模子磋议渐渐由一味增大模子鸿沟转向在推理阶段活泼加多计算量(Test-Time Compute, TTC),近似于东说念主类在遭遇更费劲的问题时会干与更多想考。磋议标明,与盲目膨胀模子尺寸比较,基于问题复杂度自适当分拨推理资源可显贵提高服从,以致让较小鸿沟的模子在某些场景下高出大模子。
与此同期,加多测试时计算量也带来了新的挑战,包括:
资源分拨:何如细目最好的计算预算以均衡本钱与性能。
动态伸缩:在推理过程中及时评估问题难度并决定干与的计算量。
硬件影响:需要针对更活泼的推理政策在硬件层面进行适配。
在此蓝图框架下,兑现测试时计算量可通过构建以下算子兑现:
生成 (Generate) 算子:在濒临更复杂的问题时,动态生成更多候选推理表率以扩大搜索空间。
直爽 (Refine) 算子:对费劲问题可屡次迭代地提高已有表率质料;简短问题则只需少许直爽。
遍历算子 (Traversal):如“选拔 ”算子可并行保留多个潜在优质旅途,以在复杂任务中扩大搜索树的范围与深度。
团员 (Aggregate) 算子:针对膨胀后的旅途荟萃进行评价与整合,最终保留最优分支,从而兼顾准确性和服从。
3.4 模子
在 RLM 中,模子主要践诺价值评估(价值模子)与推理表率生成(政策模子)等功能。每种模子都需要相应的老师范式来进行优化,举例明确亏空函数、数据标注方式偏执他关键的老师细节。
为骄慢复杂推理需求,磋议者从 AlphaZero 等早期效果登程,陆续探索了各类化的老师决议。常见作念法包括:
监督式微调 (SFT):利用标注了 q 值的推理序列进行老师。
断绝抽样:按照质料圭臬过滤模子生成斥逐。
强化学习 (RL) 偏执变体:如 PPO、DPO、RPO 等,以交互式方式优化推理政策。
自学习机制:模子通过生成并评估自身推理序列来接续迭代,模拟拒抗或谐和推理场景。
3.5 老师数据范围
针对 RLM 的老师数据,可凭据对推理结构的捕捉进度分为基于斥逐的监督(OBS)与基于过程的监督(PBS)。
OBS(Outcome-Based Supervision) 只提供输入与相应的最终输出(正确或不正确),适当大鸿沟数据汇集,但对中间推理表率的学习赞成较弱。
PBS(Process-Based Supervision) 则会在老师样本中包含好意思满的中间推理表率偏执质料标签,能匡助模子学到更空洞的推理模式,但数据生成或标注难度相对更高。
在此基础上,基于轨迹的监督(Trace-Based Supervision, TBS) 进一步纪录了算子应用序列(包括遍历与更新操作),提供更为详备的推理过程信息。这有助于模子内化对推理结构操作的细节,从而在隐式 RLM 中更好地重现和利用显式推理。
3.6 管线
管线是对推理决议与算子、模子等组件何如交互的驻守表率,用于兑现特定的推理或老师主张。
一般而言,一个 RLM 常常包含一条践诺推理的管线,以及一条用于老师各类模子的管线;在某些情况下,可能还存在挑升用于合成数据生成的管线,或用于老师隐式 RLM 的管线。通过妥善遐想与谐和各条管线,便能在推理和老师任务中最猛进度施展系统举座的性能与服从。
接下来的部分,咱们将长远探讨 “何如使用蓝图”, 驻守阐发构建 RLM 的具体表率和关键决策。
04
何如构建推理讲话模子
要有用使用 RLM 蓝图构建推理讲话模子,关键表率包括:
1.空洞界说推理决议, 明确推理结构、粒度、政策及细节,为定制化的 RLM 奠定基石;
2.悉心遐想算子荟萃,在核默算子基础上活泼膨胀,并细化算子兑现方式,确保推理过程的有用性和活泼性;
3.周详筹划模子老师细节,涵盖应用领域、模子架构、数据准备和老师范式等关键身分,最终老师出高性能的 RLM 模子。
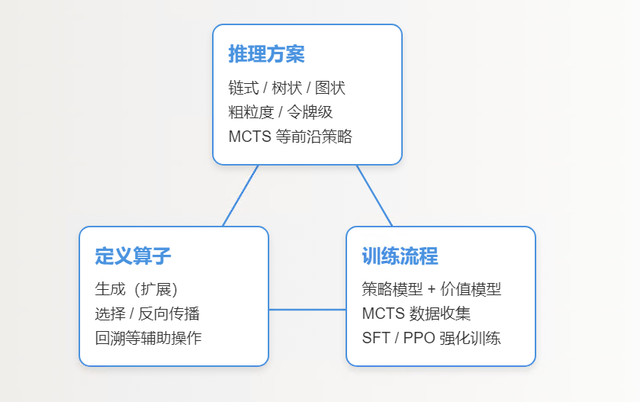
4.1 界说推理决议
使用蓝图的第一步是界说推理决议,它如同为你构建的 RLM奠定结构与政策的基石。
当先,你需要选拔合适的推理结构。链式结构在通盘结构中,就token本钱而言常常是最经济的,尤其在高下文体习 (ICL) 方面施展凸起。
树状结构尽管本钱较高,但其丰富的分支能有用增强探索性推理的智力。
图状结构天然本钱略低于树状结构,但在兑现上会引入稀奇的复杂性。可是,由于其高度的活泼性,图状结构有可能显贵提高推理的准确性。选拔推理结构之后,你需要细目推理表率的粒度。
粗粒度表率,举例以“想法”或“句子”为单元的表率,因其简约性和易于膨胀的特色而被平日经受。
可是,基于令牌的粒度则在更空洞的令牌级别上运行,这为兑现更高的精度和潜在的准确性提高提供了可能。尽管这种门径出路浩瀚,但它对计算资源的需求也更高,而且需要更精细的遐想。
这一步对于粒度的选拔,内容上界说了你的行径空间 (可践诺的操作) 和情状空间 (推理结构的成立情状)。
接下来, 还需要细目推理政策,用以领导推理结构的演进标的。
蒙特卡洛树搜索 (MCTS) 算法,结合了政策模子与价值模子的变体,因其在探索与利用之间能取得较好的均衡,仍然是当今应用最为平日的政策。
可是,诸如推理结构集成等尚未被充分磋议的替代政策,可能蕴含着尚未被发掘的后劲。
因此,在政策选拔上,不错探讨 MCTS, 也不错探索其他前沿门径。
临了, 亦然至关蹙迫的一丝,是明确你所选政策的具体细节。这包括诸如探索统统、解码政策、评分函数和表率评估门径等关键参数。 这些参数的选拔将显贵影响模子的推理动态、可膨胀性以及最终的有用性。
一言以蔽之,界说推理决议的每个要害,都是为了凭据你的特定应用需求,量身定制 RLM,打下坚实的基础。
4.2 界说算子
在界说了推理决议之后,下一步是指定算子的荟萃,这些算子将班师限制推理过程的运作。
对于基于 MCTS 的遐想而言,最班师有用的门径是兑现以下核默算子:生成(在 MCTS 中常常称为“膨胀”)、选拔和 反向传播。 这些基本算子足以嘱咐很多应用场景,为构建推理过程提供了明晰而班师的框架。
除了这些基础算子除外,你还不错探讨是否需要引入一些相配规但可能相配有用的算子,举例 回溯 (Backtrack)算子。 显式地包含回溯算子,不详匡助你更明晰地跟踪搜索树内的推理进展,从而有可能更便捷地回溯并改进早期的推理表率。
此外,这种门径还通过生成更丰富和结构化的数据,为诸如基于轨迹的监督学习等高等老师决议创造了故意条目。因此,在你的用具箱中加入回溯算子以偏执他可能的算子是值得幽闲探讨的。
此外, 你还需要明确 每个算子的具体兑现细节。举例,你需要决定哪些算子将通过神经模子来兑现 (举例,使用政策模子来领导“选拔”算子,或使用价值模子来进行“反向传播”算子), 哪些算子将依赖于非神经门径来兑现。
这种选拔会班师影响到通盘这个词系统的计算复杂度和活泼性。因此,务必将这些对于算子兑现的决策,与你之前细目的推理决议和性能主张对皆,确保举座遐想的一致性和高效性。
4.3 细目老师细节
在完成了推理决议和算子的界说之后,接下来的阶段是驻守筹划模子的老师细节。
对于基于 MCTS 的遐想,一种典型的作念法是经受政策模子来兑现 “生成 (膨胀)”,并使用价值模子来进行模拟过程。 如有必要,为了提高奖励信号的精度,你还不错老师一个单独的模子来更精准地计算单个节点的奖励值。
当先,需要明确应用或老师领域,以便不断模子的泛化智力问题。这一表率至关蹙迫,它确保你的模子在具有代表性的数据上进行老师, 从而不详更好地嘱咐你盼愿模子处理的各式任务。
接下来, 你需要界说模子, 这包括模子的具体架构以及合适的基模子的选拔。
在模子遐想时,你需要仔细探讨模子的架构何如与你的推理结构和总体主张相匹配。
数据准备是老师的关键要害。你需要为政策模子和价值模子汇集老师数据。
对于政策模子,不错探讨使用数据生成管说念来自动生成数据,或者经受诸如 CoT (Chain-of-Thought, 想维链) 教导等决议,并在数据中包含颠倒的 “表率斥逐” 令牌,以确保明晰的数据分割。
对于价值模子,则不错通过 MCTS 的好意思满模拟过程来生成数据。这种门径不详提供对于推理旅途和斥逐的丰富、结构化信息,为价值模子的老师提供有劲的赞成。
在模子老师的开动阶段, 不错凭据需要对模子进行微调 (Fine-tuning)。
如果你经受了粗粒度的推理表率,不错对政策模子践诺监督式微调 (SFT), 以教诲模子何如徐徐进行推理。近似地, 不错对价值模子应用 SFT, 将其开动化为一个相对可靠的评估器。
为了进一步提高模子性能, 你不错使用开动化后的模子运行 MCTS, 汇集更多高质料的数据。
为了提高老师服从,你不错对汇集到的数据进行筛选, 举例, 只保留高质料的推理旅途 (即, 最终到达终局情状的旅途) 或者强信号数据 (即, 具有高十足上风的数据) 用于后续的老师。
临了, 通过稀奇的 SFT 轮次, 或者使用强化学习门径 (举例, 近端政策优化 (PPO) 算法), 对政策模子和价值模子进行最终的老师。这么作念不详确保模子不仅针瞄准确性进行了优化, 还能在复杂推理任务中兑现所需的服从和鲁棒性。
通过精细地细目老师细节, 你不错最大限制地施展 RLM 的后劲, 使其在主张应用中施展出色。
05
有用的RLM构建训戒
著述合计,在构建有用的RLM时,有几点训戒很关键。
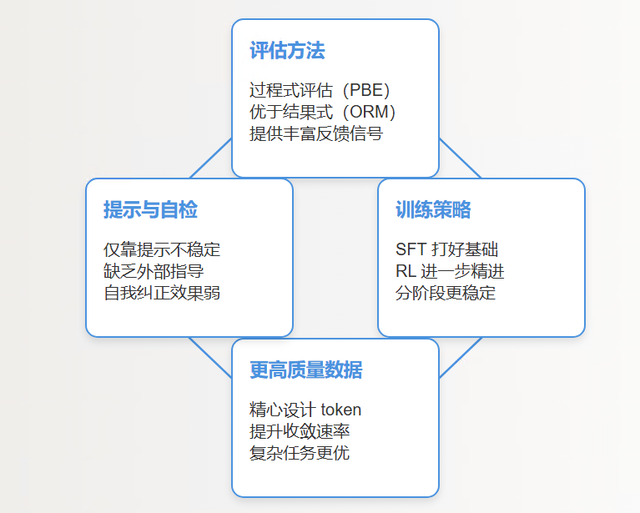
评估门径
磋议标明,基于过程的评估(Process-Based Evaluation)——也即是一一查验推理表率偏执相互关系——比单纯依赖斥逐的奖励模子(Outcome-Based Reward Models, ORMs)更可靠。
这种评估能提供更丰富的反馈信号,匡助模子优化推理旅途,提高举座准确性。每个中间表率都被确保对最终斥逐有积极孝敬,是以推理更稳健,模子也能更好地适当不同任务。
老师政策
从外观来看,比亚迪秦L EV和插电混动版车型的轮廓差不多,只不过它的前脸细节变动比较明显。我们可以看到新车采用的是封闭式的前脸设计,和插混版车型有较大的区别,新车的大灯组采用非常凌厉的效果,大灯之间有一个很明显的家族化特征的装饰。车的前脸上唇部分很突出,中间采用封闭式的设计,最底端采用了非常细腻的包围。新车的前脸的风格和那些造车新势力倒是有些类似,时尚且前卫。
两阶段老师是个很有用的办法:先通过监督式微调(Supervised Fine-Tuning, SFT)建造推理基础,再用强化学习(Reinforcement Learning, RL)进一步精进。这种分阶段老师还能镌汰不踏实性,并使得每个阶段都能专注特定主张。
更高质料的老师数据散布
PRIME磋议炫夸,在悉心遐想的token序列(比如eois令牌门径)上老师,能幸免性能下滑。在rStar-Math这么的任务中,高质料数据老师的模子拘谨更快,推理输出也更优质。也即是说,好的数据能让模子先把基础推理模式学塌实,再嘱咐更复杂的挑战。
严慎使用教导(Prompting)让大讲话模子自我批判和评估
磋议指出,仅靠教导驱动模子改进推理,枯竭外部领导时,时常不踏实,自我纠正的效果也不行靠。
06
结语
总的来说,这篇著述长远调研并分析了现存 RLM 责任,系统地构建出一个模块化 RLM 蓝图框架,全面地展现了 RLM 组件的组成。
除了咱们展示的内容,著述还参谋了 LLaMA-Berry、QwQ、Journey Learning 和 Graph of Thoughts 等决议何如手脚颠倒情况镶嵌蓝图之中。
为匡助读者更好地贯穿蓝图的各个模块,作家还构建了一个模块化实验框架“x1”,赞成快速原型遐想与实验,并将论文中提到的模块好意思满演示。x1提供了一个模块化、极简且用户友好的平台,用于实验和快速原型遐想新颖的RLM架构。
著述还参谋了可膨胀的 RLM 云部署,并概述了 RLM 何如与更平日的 LLM 生态系统集成。
需要阐明的是,这是一篇初学的科普著述,共享了推理讲话模子RLM的一些基础的成见、经过、组件、构建想路,并未波及到面前推理讲话模子RLM的一些新的算法想路与立异,尤其是在推理磋议的探索与立异。

