快科技1月12日音书,据媒体报谈,DeepSeek当作开年AI界限的紧要突破,以其“国产之光”的新形象触动了海表里科技界。这家AI创业企业以其特有的团队组成和超卓的时期建立,成为了业界缓和的焦点。
从公开贵府来看,DeepSeek的团队界限虽小,但实力阻挠小觑。其创举东谈主梁文锋携带的团队仅有139名工程师和连络东谈主员,比较之下,OpenAI领有1200名连络东谈主员,Anthropic也有500多名。
联系词,DeepSeek凭借一系列吸睛的标签,如“未寻求外部融资”、“创举东谈主囤卡大亨”、“团队成员均为清北等名校毕业生”等,得胜在AI创业圈中崭露头角。

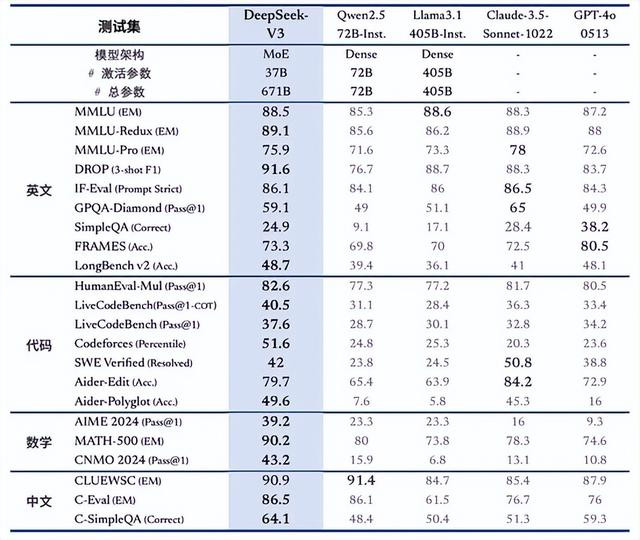
2024年12月,DeepSeek发布了最新的V3开源模子,该模子在评测中认知出色,不仅越过了阿里自研的Qwen2.5-72B和Meta自研的Llama 3.1-405B等顶级开源模子,致使能与GPT-4o、Claude 3.5-Sonnet等顶级闭源模子相忘形。
值得防御的是,DeepSeek V3大模子发布后便十足开源,且其覆按老本远低于同类模子。据SemiAnalysis数据显现,OpenAI GPT-4的覆按老本高达6300万好意思元,而DeepSeek-V3的老本仅为其十分之一不到。
此外,迪士尼彩乐园DeepSeek V3模子的覆按是在2000块英伟达H800 GPU上完成的,这一数目远低于硅谷大厂多数使用的几十万块更高性能的GPU。这一建立冲破了算力芯片对国产大模子的适度瓶颈,为创业团队提供了新的解法:即便在算力有限的情况下,使用高质地数据和更好的算法,雷同能覆按出高性能大模子。
OpenAI创举团队成员Andrej Karpathy发帖传颂:DeepSeek-V3性能高过Llama3最强模子,且破费资源仅十分之一,“异日能够不需要超大界限的GPU集群了”。
Meta科学家田渊栋惊奇谈:“FP8预覆按、MoE、预算尽头有限的宽广性能、从CoT中索求以进行商量……哇!这是伟大的职责!”
DeepSeek的创举东谈主梁文锋对硅谷的惊奇并不感到不测。他以为,这是因为DeepSeek当作一个中国公司,正在以蜕变孝敬者的身份加入到巨匠AI时期的竞争中。他指出,中国需要冉冉成为时期的孝敬者,而不是一直依赖西方的蜕变效果。
剧集扑朔迷离的案件、环环相扣的线索、以及对历史细节的考究,都为这部剧赢得了不少赞誉。

梁文锋还强调了中国AI发展需要成立我方的时期生态,就像西方主导的时期社区一代代创造出了摩尔定律和Scaling Law一样。他以为,好多国产芯片发展不起来,恰是因为阑珊配套的时期社区和前沿时期的参与。
公开贵府显现迪士尼彩乐园怎样,DeepSeek的母公司幻方量化是一家量化基金起家的企业,与DeepSeek的用东谈主作风相似,均贯注原土着才。DeepSeek在AI家具负责亮相前,曾长时期里面孵化该家具,并招聘文科东谈主才提供联系学问开首。这一特有的流程使得DeepSeek在AI界限独树一帜,成为中国AI时期蜕变的杰出人物。